

Introducing Machine Learning through a comparison of supervised learning vs unsupervised learning.
What is Machine Learning?
Multiple ways of seeing Machine Learning
Machine Learning is all about data and, as its name suggests, about learning from it. You may have encountered (or not, if you’re novice to the field) numerous articles which introduce Machine Learning in terms of modelling aspects. For example, we always start by seeing how Linear Regression is a basic model that can be extended into more complex Neural Networks, which form a part of Supervised Learning approaches…
For now, let’s forget about that. Not that it’s not accurate, but I would rather say that introducing Machine Learning, and especially the differences between Supervised Learning and Unsupervised Learning, should be done with respect to data. Data in Machine Learning is everything. Without it, you can’t make your system learn anything. More importantly, every problem should be driven by data: the specificities of your data are going to lead you to the questions you will try to solve with Machine Learning.
If we want to see Machine Learning through the lens of data, we first need to understand what data is. Try and describe what data is to you. You may encounter difficulties to do so, but you probably won’t have the same answer as the next person reading this article. But why would you? You come from different backgrounds, and there are multiple ways of seeing data.
Generally, we think about data as being an ensemble of lots of numbers, sometimes categorical values, which can be gathered in tables:

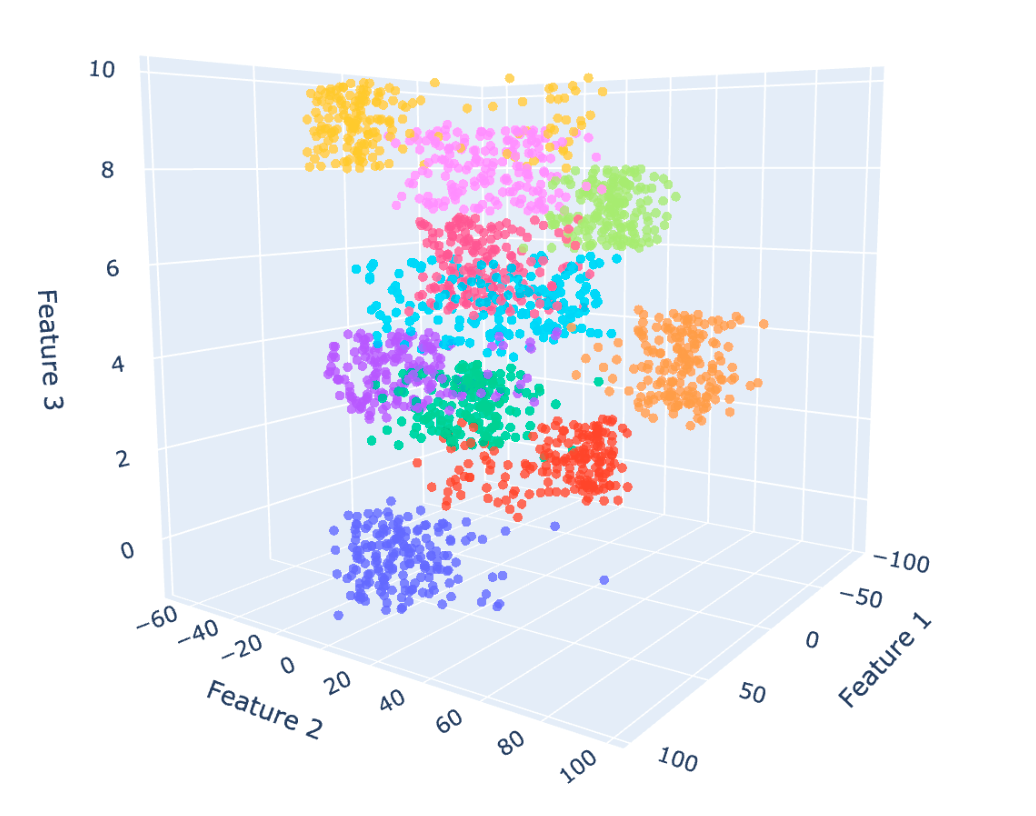
Understanding Machine Learning with distributions
In Machine Learning, we need to think about data in mathematical terms. By that, it means that data should be seen as a distribution of points over a multi-dimensional space, which can potentially be quite large. In the dataset above, the samples (or data points, instances, whatever you want to call them) are distributed along a D-dimensional space, where each dimension is a particular feature. Of course, it’s difficult to conceptualise what is a distribution in a such a high dimensional space, so let’s plot 3 of the features and see what it looks like:
As you can already see, the distribution of this data is not random. It has some inner specificities, some features seem to be more or less correlated, but also some groups emerge. Well, you just naturally pinpointed what is Machine Learning: the core principle of Machine Learning is to build a system that understands the specificities of a data distribution. But what does “understanding” mean concretely? Well, in practice, you only have access to a limited part of the distribution. For example, you may have gathered a dataset about cars and their features. However, it is likely that you won’t have an entry for every car on the planet, mainly because there are too many of them, and also because at each moment in time, new cars are being built. In this context, understanding data means to be able to learn intrinsic characteristics of the data distribution based on the part we have access to.
The objectives of every Machine Learning task
To what goal? What should be understood by your Machine Learning system depends entirely on the data available to you and the goals you plan to achieve with that data. For example, let’s say you are a retailer and you want to make more money. Depending on the data you have at your disposal, you might want to better plan your sales of each item category, because it would allow you to know exactly when to make orders to suppliers and therefore hardly run out of stock. From the data you have, you can derive these characteristics, and then generalise to unseen (in this case future) data. The generalisation aspect is the key of all Machine Learning systems: we learn from already available data, and generalise in production to new incoming data.
Supervised Learning vs Unsupervised Learning
Now that you see data as a multidimensional distribution, and that we stated that the goal of Machine Learning is to understand it, the distinction between Supervised Learning vs Unsupervised Learning should be fairly easy to grasp.
Supervised Learning
In Supervised Learning, a particular feature of interest is set aside, and the goal is to understand how the other features impact this target. For example, in our above distribution, the goal can be to predict Feature 3 based on the other features. To which purpose? Well in newly incoming data, you may not have access to this particular feature, but it might be necessary for you to know it. In the retail example, you may want to predict sales in a month, based on the fashion trends today. The mathematical problem behind it is to build a system that learns the mapping feature_3 = f(feature_1, feature_2), which we can also visualise in 2D, having the values of Feature 3 being colorized:
Once again, we want to learn such a mapping from available data, to be able to extend it to future incoming samples, where Feature 3 is not available but necessary to address our main goal. In production, we would only have access to Features 1 and 2 for the incoming data:
The example we just saw aims at learning a continuous mapping, in other words it is a regression problem. The target feature can also be discrete (or categorical). The process is exactly the same, but the mapping problem would be a classification task.
Unsupervised learning
Unlike supervised approaches, Unsupervised Learning tasks do not focus on studying a particular feature, but rather aim at understanding the data as a whole. In practice, we generally try to detect patterns in the data and organise it. For example, by playing with the first plot of this article, you may have distinguished potential groups of data points. Well, the process of building collections this way is called clustering and is one of the most applied unsupervised learning strategies.
In the same way as supervised learning tasks, the goal is to build a model of a particular aspect of the data, so that new incoming instances can be identified with respect to that model. In the case of clustering, it simply manifests as assigning new points to previously identified clusters.
The field of Unsupervised Learning is actually really broad. In addition to clustering, we can find anomaly detection by outliers exposure. Or also various component analysis techniques, which aim at exposing and/or combining the most useful features to reduce the dimensionality of the data (this can help a lot in decreasing the computation time of supervised models training, but also in building an interpretation of the models decision process).
What should you retain?
In short, Machine Learning is about getting insights about a data distribution from available samples, to be able to infer things about new and previously unseen instances. The two main and most common categories of Machine Learning tasks, Unsupervised and Supervised Learning, both try to achieve this goal. What distinguishes the two is that in Supervised Learning, the insights we get are driven towards a particular feature, which leads to learning a mapping between this target and the other features.
On the other hand, the tasks which fall under the Unsupervised Learning category aim at understanding data in its entirety. For example, extracting clusters, or understanding how we can combine features to reduce the dimensionality of the data while still keeping sensible information.

Now that you have grasped the specificities of Supervised Learning vs Unsupervised Learning techniques, you might be wondering when you should use them in your ML pathway. While we generally try to use supervised approaches to train end tasks, it requires a target feature to be modelled. The lack of proper labelled data can be a significant problem for this. In this case, unsupervised learning models can provide you with interesting insights to still get you through your problems. As mentioned before, they can even be used as a data processing step before applying supervised learning techniques, for example by reducing the dimensionality of your data to speed up training processes.